Convolutional Neural Network
Ein Convolutional Neural Network (CNN oder ConvNet), zu Deutsch etwa „faltendes neuronales Netzwerk“, ist ein künstliches neuronales Netz. Es handelt sich um ein von biologischen Prozessen inspiriertes Konzept im Bereich des maschinellen Lernens[1]. Convolutional Neural Networks finden Anwendung in zahlreichen Technologien der künstlichen Intelligenz, vornehmlich bei der maschinellen Verarbeitung von Bild- oder Audiodaten.
Die CNN-Architektur wurde von Kunihiko Fukushima unter dem Namen Neocognitron eingeführt.[2][3] Alex Waibels CNN namens TDNN (1987) wurde durch Backpropagation trainiert und erzielte Bewegungsinvarianz.[4] Auch Yann LeCun publizierte wichtige Beiträge zu CNNs.[5][6]
Aufbau
[Bearbeiten | Quelltext bearbeiten]
Grundsätzlich besteht die Struktur eines klassischen Convolutional Neural Networks aus einem oder mehreren Convolutional Layer, gefolgt von einem Pooling Layer. Diese Einheit kann sich prinzipiell beliebig oft wiederholen, bei ausreichend Wiederholungen spricht man dann von Deep Convolutional Neural Networks, die in den Bereich Deep Learning fallen. Hierbei ist auf die Ähnlichkeit zum Optimalfilter hinzuweisen[7]. Architektonisch können im Vergleich zum mehrlagigen Perzeptron (Multi-Layer-Perzeptron) drei wesentliche Unterschiede festgehalten werden (Details hierzu siehe Convolutional Layer):
- 2D- oder 3D-Anordnung der Neuronen
- Geteilte Gewichte
- Lokale Konnektivität
Convolutional Layer
[Bearbeiten | Quelltext bearbeiten]In der Regel liegt die Eingabe als zwei- oder dreidimensionale Matrix (z. B. die Pixel eines Graustufen- oder Farbbildes) vor. Dementsprechend sind die Neuronen im Convolutional Layer angeordnet.
Die Aktivität jedes Neurons wird über eine diskrete Faltung (daher der Zusatz convolutional) berechnet. Dabei wird schrittweise eine vergleichsweise kleine Faltungsmatrix (Filterkernel) über die Eingabe bewegt. Die Eingabe eines Neurons im Convolutional Layer berechnet sich als inneres Produkt des Filterkernels mit dem aktuell unterliegenden Bildausschnitt. Dementsprechend reagieren benachbarte Neuronen im Convolutional Layer auf sich überlappende Bereiche (ähnliche Frequenzen in Audiosignalen oder lokale Umgebungen in Bildern).[8]

Hervorzuheben ist, dass ein Neuron in diesem Layer nur auf Reize in einer lokalen Umgebung des vorherigen Layers reagiert. Dies folgt dem biologischen Vorbild des rezeptiven Feldes. Zudem sind die Gewichte für alle Neuronen eines Convolutional Layers identisch (geteilte Gewichte, englisch: shared weights). Dies führt dazu, dass beispielsweise jedes Neuron im ersten Convolutional Layer codiert, zu welcher Intensität eine Kante in einem bestimmten lokalen Bereich der Eingabe vorliegt. Die Kantenerkennung als erster Schritt der Bilderkennung besitzt hohe biologische Plausibilität.[9] Aus den shared weights folgt unmittelbar, dass Translationsinvarianz eine inhärente Eigenschaft von CNNs ist.
Der mittels diskreter Faltung ermittelte Input eines jeden Neurons wird nun von einer Aktivierungsfunktion, bei CNNs üblicherweise Rectified Linear Unit, kurz ReLU (), in den Output verwandelt, der die relative Feuerfrequenz eines echten Neurons modellieren soll. Da Backpropagation die Berechnung der Gradienten verlangt, wird in der Praxis eine differenzierbare Approximation von ReLU benutzt:
Analog zum visuellen Cortex steigt in tiefer gelegenen Convolutional Layers sowohl die Größe der rezeptiven Felder (siehe Sektion Pooling Layer) als auch die Komplexität der erkannten Features (beispielsweise Teile eines Gesichts).
Eine Faltung ist die einfache Anwendung eines Filters auf eine Eingabe, die zu einer Aktivierung führt. Die wiederholte Anwendung desselben Filters auf eine Eingabe führt zu einer Karte von Aktivierungen, die als Feature Map bezeichnet wird und die Positionen und die Stärke eines erkannten Features in einer Eingabe, beispielsweise einem Bild, angibt. Convolutional Layer können automatisch eine große Anzahl von Filtern parallel lernen, die für einen Trainingsdatensatz spezifisch sind. Das Ergebnis sind hochspezifische Merkmale, die überall auf Eingabebildern erkannt werden können. Convolutional Layer wenden einen Filter auf eine Eingabe an, um eine Feature Map zu erstellen, die das Vorhandensein erkannter Features in der Eingabe zusammenfasst.
Eine Faltung ist eine lineare Operation, die die Multiplikation einer Reihe von Gewichten mit der Eingabe beinhaltet, ähnlich wie bei einem herkömmlichen neuronalen Netz. Der Filter ist kleiner als die Eingabedaten und die Art der Multiplikation, die zwischen einem filtergroßen Patch der Eingabe und dem Filter angewendet wird, ist ein Skalarprodukt. Die Verwendung eines Filters, der kleiner als die Eingabe ist, ist beabsichtigt, weil dadurch derselbe Filter an verschiedenen Stellen der Eingabe mehrmals mit dem Eingabearray multipliziert werden kann. Konkret wird der Filter systematisch auf jeden überlappenden Teil oder filtergroßen Patch der Eingabedaten angewendet, von links nach rechts, von oben nach unten. Diese systematische Anwendung desselben Filters auf ein Bild ist eine wirkungsvolle Idee. Wenn der Filter darauf ausgelegt ist, einen bestimmten Merkmalstyp in der Eingabe zu erkennen, kann der Filter dieses Merkmal an einer beliebigen Stelle im Bild erkennen. Diese Fähigkeit wird allgemein als Übersetzungsinvarianz bezeichnet, zum Beispiel das allgemeine Interesse daran, ob das Merkmal vorhanden ist, und nicht, wo es vorhanden war.[10]
Die Convolutional Layer ist der Kernbaustein des Convolutional Neural Network. Es trägt den Hauptanteil der Rechenlast des Netzwerks. Diese Schicht führt ein Skalarprodukt zwischen zwei Matrizen aus, wobei eine Matrix der Satz von gelernten Parametern ist, die auch als Kernel bezeichnet werden, und die andere Matrix der eingeschränkte Teil des Empfangsfeldes. Der Kernel ist räumlich kleiner als ein Bild, ist aber ausführlicher. Dies bedeutet, dass, wenn das Bild aus drei Kanälen besteht, die Höhe und die Breite des Kernels räumlich klein sind, die Tiefe bis zu allen drei Kanälen erstreckt. Dies erzeugt eine zweidimensionale Darstellung des als Aktivierungskarte bekannten Bildes, die die Antwort des Kernels an jeder räumlichen Position des Bildes ergibt. Die Gleitgröße des Kernels wird als Schritt bezeichnet.
Wenn man eine Eingabe der Größe und Kerne mit einer räumlichen Größe von mit Schrittweite und dem Betrag der Füllung hat, kann die Größe des Ausgabevolumens durch die folgende Formel bestimmt werden:[11]
Pooling Layer
[Bearbeiten | Quelltext bearbeiten]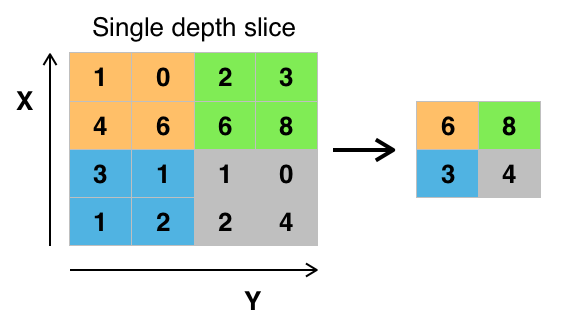
Im folgenden Schritt, dem Pooling, werden überflüssige Informationen verworfen. Zur Objekterkennung in Bildern etwa ist die exakte Position einer Kante im Bild von vernachlässigbarem Interesse – die ungefähre Lokalisierung eines Features ist hinreichend. Es gibt verschiedene Arten des Poolings. Mit Abstand am stärksten verbreitet ist das Max-Pooling[12][13][14], wobei aus jedem 2×2-Quadrat aus Neuronen des Convolutional Layers nur die Aktivität des aktivsten (daher „Max“) Neurons für die weiteren Berechnungsschritte beibehalten wird; die Aktivität der übrigen Neuronen wird verworfen (siehe Bild). Trotz der Datenreduktion (im Beispiel 75 %) verringert sich in der Regel die Performance des Netzwerks nicht durch das Pooling. Im Gegenteil, es bietet einige signifikante Vorteile:
- Verringerter Platzbedarf und erhöhte Berechnungsgeschwindigkeit
- Daraus resultierende Möglichkeit zur Erzeugung tieferer Netzwerke, die komplexere Aufgaben lösen können
- Automatisches Wachstum der Größe der rezeptiven Felder in tieferen Convolutional Layers (ohne dass dafür explizit die Größe der Faltungsmatrizen erhöht werden müsste)
- Präventionsmaßnahme gegen Overfitting
Alternativen wie das Mean-Pooling haben sich in der Praxis als weniger effizient erwiesen.[15]
Das biologische Pendant zum Pooling ist die laterale Hemmung im visuellen Cortex.
Die Pooling Layer ersetzt die Ausgabe des Netzwerks an bestimmten Stellen, indem er eine zusammenfassende Statistik der nahe gelegenen Ausgaben abgeleitet hat. Dies hilft bei der Verringerung der räumlichen Größe der Darstellung, die die erforderliche Menge an Rechen und Gewichten verringert. Die Pooling-Operation wird auf jedem Stück der Darstellung einzeln ausgeführt. Das beliebteste Verfahren ist Max Pooling, die die maximale Ausgabe aus der Nachbarschaft angibt. Wenn man eine Aktivierungskarte der Größe , einen Pooling Kernel der räumlichen Größe mit Schrittweite hat, kann die Größe des Ausgabevolumens durch die folgende Formel bestimmt werden:[11]
Dies ergibt ein Ausgabevolumen der Größe .
Max Pooling
[Bearbeiten | Quelltext bearbeiten]Max Pooling ist eine Faltungstechnik, die den Maximalwert aus dem Patch der Eingabedaten auswählt und diese Werte in einer Feature Map zusammenfasst: Diese Methode behält die wichtigsten Merkmale der Eingabe bei, indem sie ihre Abmessungen reduziert. Die mathematische Formel für Max Pooling lautet:
Dabei sind die Eingabe, die Indexe der Ausgabe, der Kanalindex, und die Schrittwerte in horizontaler bzw. vertikaler Richtung und das Pooling-Fenster wird durch die Filtergrößen und definiert, zentriert am Ausgabeindex .
Average Pooling
[Bearbeiten | Quelltext bearbeiten]Durch das Average Pooling wird der Durchschnittswert aus einem Bereich von Eingabedaten berechnet und diese Werte in einer Feature Map zusammengefasst. Diese Methode ist in Fällen vorzuziehen, in denen eine Glättung der Eingabedaten erforderlich ist, da sie dabei hilft, das Vorhandensein von Ausreißern zu identifizieren. Die mathematische Formel für Average Pooling lautet:
Global Pooling
[Bearbeiten | Quelltext bearbeiten]Global Pooling fasst die Werte aller Neuronen für jeden Patch der Eingabedaten in einer Feature Map zusammen, unabhängig von ihrer räumlichen Position. Diese Technik wird auch verwendet, um die Dimensionalität der Eingabe zu reduzieren und kann entweder mithilfe der maximalen oder durchschnittlichen Pooling-Operation durchgeführt werden. Die mathematische Formel für Global Pooling lautet:
Stochastic Pooling
[Bearbeiten | Quelltext bearbeiten]Stochastic Pooling ist eine nicht-deterministische Pooling-Operation, die zufällige Werte mit Max Pooling kombiniert. Diese Technik trägt dazu bei, die Robustheit des Modells gegenüber kleinen Abweichungen in den Eingabedaten zu verbessern. Die mathematische Formel für Stochastic Pooling lautet:
Dabei ist die Eingabe, die Indexe des Ausgabetensors, der Kanalindex und die Wahrscheinlichkeit, den Wert an Position in der Feature Map der Eingabe beizubehalten. Die Wahrscheinlichkeiten werden für jedes Pooling-Fenster zufällig generiert und sind normalerweise proportional zu den Werten im Fenster.
Fully-connected Layer
[Bearbeiten | Quelltext bearbeiten]Nach einigen sich wiederholenden Einheiten bestehend aus Convolutional und Pooling Layer kann das Netzwerk mit einem (oder mehreren) Fully-connected Layer entsprechend der Architektur des mehrlagigen Perzeptrons abschließen. Dies wird vor allem bei der Klassifizierung angewendet. Die Anzahl der Neuronen im letzten Layer korrespondiert dann üblicherweise zu der Anzahl an (Objekt-)Klassen, die das Netz unterscheiden soll. Dieses, sehr redundante, sogenannte One-Hot-encoding hat den Vorteil, dass keine impliziten Annahmen über Ähnlichkeiten von Klassen gemacht werden.
Die Ausgabe der letzten Schicht des CNNs wird in der Regel durch eine Softmax-Funktion, einer translations- aber nicht skaleninvarianten Normalisierung über alle Neuronen im letzten Layer, in eine Wahrscheinlichkeitsverteilung überführt.
Convolution Operator
[Bearbeiten | Quelltext bearbeiten]Der Convolution Operator ist definiert als Faltung auf den reellen Funktionen und :[16]
Die Zeit wird meistens diskret definiert:
In Anwendungen mit zweidimensionalen Arrays als Input und Kern gilt
Der Convolution Operator ist kommutativ, d. h. es gilt
Außerdem gilt die Cross-Relation:[17]
Training
[Bearbeiten | Quelltext bearbeiten]CNNs werden in aller Regel überwacht trainiert. Während des Trainings wird dabei für jeden gezeigten Input der passende One-Hot-Vektor bereitgestellt. Via Backpropagation wird der Gradient eines jeden Neurons berechnet und die Gewichte werden in Richtung des steilsten Abfalls der Fehleroberfläche angepasst.
Interessanterweise haben drei vereinfachende Annahmen, die den Berechnungsaufwand des Netzes maßgeblich verringern und damit tiefere Netzwerke zulassen, wesentlich zum Erfolg von CNNs beigetragen.
- Pooling – Hierbei wird der Großteil der Aktivität eines Layers schlicht verworfen.
- ReLU – Die gängige Aktivierungsfunktion, die jeglichen negativen Input auf 0 projiziert.
- Dropout – Eine Regularisierungsmethode beim Training, die Overfitting verhindert. Dabei werden pro Trainingsschritt zufällig ausgewählte Neuronen aus dem Netzwerk entfernt.
Expressivität und Notwendigkeit
[Bearbeiten | Quelltext bearbeiten]Da CNNs eine Sonderform von mehrlagigen Perzeptrons darstellen,[18] sind sie prinzipiell identisch in ihrer Ausdrucksstärke.
Der Erfolg von CNNs lässt sich mit ihrer kompakten Repräsentation der zu lernenden Gewichte („shared weights“) erklären. Grundlage ist die Annahme, dass ein potentiell interessantes Feature (In Objekterkennung etwa Kanten) an jeder Stelle des Inputsignals (des Bildes) interessant ist. Während ein klassisches zweilagiges Perzeptron mit jeweils 1000 Neuronen pro Ebene für die Verarbeitung von einem Bild im Format 32 × 32 insgesamt mehr als 2 Millionen Gewichte benötigt, verlangt ein CNN mit zwei sich wiederholenden Einheiten, bestehend aus insgesamt 13.000 Neuronen, nur 160.000 (geteilte) zu lernende Gewichte, wovon der Großteil im hinteren Bereich (fully-connected Layer) liegt.
Neben dem wesentlich verringerten Arbeitsspeicherbedarf, haben sich geteilte Gewichte als robust gegenüber Translations-, Rotations-, Skalen- und Luminanzvarianz erwiesen.[18]
Um mithilfe eines mehrlagigen Perzeptrons eine ähnliche Performance in der Bilderkennung zu erreichen, müsste dieses Netzwerk jedes Feature für jeden Bereich des Inputsignals unabhängig erlernen. Dies funktioniert zwar ausreichend für stark verkleinerte Bilder (etwa 32 × 32), aufgrund des Fluchs der Dimensionalität scheitern MLPs jedoch an höher auflösenden Bildern.
Biologische Plausibilität
[Bearbeiten | Quelltext bearbeiten]CNNs können als ein vom visuellen Cortex inspiriertes Konzept verstanden werden, sind jedoch weit davon entfernt, neuronale Verarbeitung plausibel zu modellieren.
Einerseits gilt das Herzstück von CNNs, der Lernmechanismus Backpropagation, als biologisch unplausibel, da es bis heute trotz intensiver Bemühungen nicht gelungen ist, neuronale Korrelate von backpropagation-ähnlichen Fehlersignalen zu finden.[19][20] Neben dem stärksten Gegenargument zur biologischen Plausibilität – der Frage, wie der Kortex Zugriff auf das Zielsignal (Label) bekommt – listen Bengio et al. weitere Gründe, darunter die binäre, zeitkontinuierliche Kommunikation biologischer Neurone sowie die Berechnung nicht-linearer Ableitungen der Vorwärtsneuronen[20].
Andererseits konnte durch Untersuchungen mit fMRT gezeigt werden, dass Aktivierungsmuster einzelner Schichten eines CNNs mit den Neuronenaktivitäten in bestimmten Arealen des visuellen Cortex korrelieren, wenn sowohl das CNN als auch die menschlichen Testprobanden mit ähnlichen Aufgaben aus der Bildverarbeitung konfrontiert werden.[21][22] Neuronen im primären visuellen Cortex, die sogenannten „simple cells“, reagieren auf Aktivität in einem kleinen Bereich der Retina. Dieses Verhalten wird in CNNs durch die diskrete Faltung in den convolutional Layers modelliert. Funktional sind diese biologischen Neuronen für die Erkennung von Kanten in bestimmten Orientierungen zuständig. Diese Eigenschaft der simple cells kann wiederum mithilfe von Gabor-Filtern präzise modelliert werden.[23][24] Trainiert man ein CNN zur Objekterkennung, konvergieren die Gewichte im ersten Convolutional Layer ohne jedes „Wissen“ über die Existenz von simple cells gegen Filtermatrizen, die Gabor-Filtern erstaunlich nahe kommen[25], was als Argument für die biologische Plausibilität von CNNs verstanden werden kann. Angesichts einer umfassenden statistischen Informationsanalyse von Bildern mit dem Ergebnis, dass Ecken und Kanten in verschiedenen Orientierungen die am stärksten voneinander unabhängigen Komponenten in Bildern – und somit die fundamentalsten Grundbausteine zur Bildanalyse – sind, ist dies jedoch zu erwarten.[26]
Somit treten die Analogien zwischen Neuronen in CNNs und biologischen Neuronen primär behavioristisch zutage, also im Vergleich zweier funktionsfähiger Systeme, wohingegen die Entwicklung eines „unwissenden“ Neurons zu einem (beispielsweise) gesichtserkennenden Neuron in beiden Systemen diametralen Prinzipien folgt.
Probleme
[Bearbeiten | Quelltext bearbeiten]Neuronale Feedforward Netze können jede stetige Funktion der Form annähern, dies wird durch das universelle Approximationstheorem garantiert. Es gibt jedoch keine Garantie dafür, dass das Training dies auch ermöglicht. Wird während dem Training keine Regularisierung verwendet, wird ein neuronales Netz überangepasst auf das Rauschen in den Trainingsdaten. Durch die Verringerung der Modellkapazität durch Wiederverwendung der Gewichte mithilfe einer Faltung (als eine bestimmte Art der Regularisierung) kann die Tendenz zur Überanpassung verringert werden. Formal bedeutet dies, dass die Merkmale transformiert werden, so dass, wenn die Entropie von ist, dann gilt . Dadurch kann das neuronale Netz eine neue Zielfunktion lernen, die weniger anfällig für Überanpassung ist. Dies wird dadurch ermöglicht, dass eine wichtige Voraussetzung, die lineare Unabhängigkeit der Merkmale, für einige Datenklassen systematisch verletzt wird.[27]
Anwendung
[Bearbeiten | Quelltext bearbeiten]Seit dem Einsatz von Grafikprozessor-Programmierung können CNNs erstmals effizient trainiert werden.[28] Sie gelten als State-of-the-Art-Methode für zahlreiche Anwendungen im Bereich der Klassifizierung.
Bilderkennung
[Bearbeiten | Quelltext bearbeiten]CNNs erreichen eine Fehlerquote von 0,23 % auf eine der am häufigsten genutzten Bilddatenbanken, MNIST, was (Stand 2016) der geringsten Fehlerquote aller jemals getesteten Algorithmen entspricht.[29]
Im Jahr 2012 verbesserte ein CNN (AlexNet) die Fehlerquote beim jährlichen Wettbewerb der Benchmark-Datenbank ImageNet (ILSVRC) von dem vormaligen Rekord von 25,8 % auf 16,4 %. Seitdem nutzen alle vorne platzierten Algorithmen CNN-Strukturen. Im Jahr 2016 wurde eine Fehlerquote < 3 % erreicht.[30]
Auch im Bereich der Gesichtserkennung konnten bahnbrechende Resultate erzielt werden.[31]
Spracherkennung
[Bearbeiten | Quelltext bearbeiten]CNNs werden erfolgreich zur Spracherkennung eingesetzt und haben hervorragende Resultate in folgenden Bereichen erzielt:
- semantisches Parsen[32]
- Suchanfragenrückerkennung[33]
- Satzmodellierung[34]
- Satzklassifizierung[35]
- Part-of-speech-Tagging[36]
- Maschinelle Übersetzung (z. B. verwendet im Online-Dienst DeepL)[37]
Reinforcement Learning
[Bearbeiten | Quelltext bearbeiten]Angewendet werden können CNNs auch im Bereich Reinforcement Learning, bei dem ein CNN mit Q-Learning kombiniert wird. Das Netzwerk wird darauf trainiert zu schätzen, welche Aktionen bei einem gegebenen Zustand zu welchem zukünftigen Gewinn führen. Durch die Verwendung eines CNNs können so auch komplexe, höher-dimensionale Zustandsräume betrachtet werden, wie etwa die Bildschirmausgabe eines Videospiels.[38]
Landwirtschaft
[Bearbeiten | Quelltext bearbeiten]CNNs werden heutzutage auch eingesetzt, um die Auswirkungen von Düngung vorherzusagen und Düngungsempfehlungen abzugeben.[39][40]
Literatur
[Bearbeiten | Quelltext bearbeiten]- Ian Goodfellow, Yoshua Bengio, Aaron Courville: Deep Learning (= Adaptive Computation and Machine Learning). MIT Press, 2016, ISBN 978-0-262-03561-3, 9 Convolutional Networks (Online).
Weblinks
[Bearbeiten | Quelltext bearbeiten]- TED-Talk: How we are teaching computers to understand pictures – Fei Fei Li, März 2015, abgerufen am 17. November 2016.
- 2D-Visualisierung der Aktivität eines zweilagigen CNNs, abgerufen am 17. November 2016.
- Tutorial zur Implementierung eines CNN mithilfe der Python-Bibliothek TensorFlow
- CNN-Tutorial der University of Stanford, inklusive Visualisierung erlernter Faltungsmatrizen, abgerufen am 17. November 2016.
- Gradient-Based Learning Applied to Document Recognition, Y. Le Cun et al (PDF; 933 kB), erste erfolgreiche Anwendung eines CNN, abgerufen am 17. November 2016.
- ImageNet Classification with Deep Convolutional Neural Networks, A. Krizhevsky, I. Sutskever and G. E. Hinton, AlexNet – Durchbruch in der Bilderkennung, Gewinner der ILSVRC-Challenge 2012.
Einzelnachweise
[Bearbeiten | Quelltext bearbeiten]- ↑ Masakazu Matsugu, Katsuhiko Mori, Yusuke Mitari, Yuji Kaneda: Subject independent facial expression recognition with robust face detection using a convolutional neural network. In: Neural Networks. Band 16, Nr. 5, 2003, S. 555–559, doi:10.1016/S0893-6080(03)00115-1 (Online [PDF; abgerufen am 28. Mai 2017]).
- ↑ Kunihiko Fukushima: Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position. In: Biological Cybernetics. Band 36, Nr. 4, 1980, S. 193–202, doi:10.1007/BF00344251 (Online [PDF]).
- ↑ Jürgen Schmidhuber: Deep Learning in Neural Networks: An Overview. In: Neural Networks. Band 61, 2015, S. 85–117, doi:10.1016/j.neunet.2014.09.003, arxiv:1404.7828.
- ↑ Alex Waibel: Phoneme Recognition Using Time-Delay Neural Networks. Meeting of the Institute of Electrical, Information and Communication Engineers (IEICE), Tokyo, Japan, 1987. 1987 (englisch).
- ↑ Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel, Backpropagation Applied to Handwritten Zip Code Recognition; AT&T Bell Laboratories, 1989
- ↑ Yann LeCun, Leon Bottou, Yoshua Bengio, Patrick Haffner: Gradient-based Learning Applied to Document Recognition. In: Proceedings of the IEEE. 1998 (lecun.com [PDF]).
- ↑ Convolutional Neural Networks Demystified: A Matched Filtering Perspective Based Tutorial https://arxiv.org/abs/2108.11663v3
- ↑ unknown: Convolutional Neural Networks (LeNet). Archiviert vom (nicht mehr online verfügbar) am 28. Dezember 2017; abgerufen am 17. November 2016 (englisch). Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.
- ↑ D. H. Hubel, T. N. Wiesel: Receptive fields and functional architecture of monkey striate cortex. In: The Journal of Physiology. Band 195, Nr. 1, 1. März 1968, ISSN 0022-3751, S. 215–243, doi:10.1113/jphysiol.1968.sp008455, PMID 4966457, PMC 1557912 (freier Volltext).
- ↑ Jason Brownlee, Machine Learning Mastery: How Do Convolutional Layers Work in Deep Learning Neural Networks?
- ↑ a b Mayank Mishra, Towards Data Science: Convolutional Neural Networks, Explained
- ↑ J Weng, N Ahuja, TS Huang: Learning recognition and segmentation of 3-D objects from 2-D images. In: Proc. 4th International Conf. Computer Vision. 1993, S. 121–128, doi:10.1109/ICCV.1993.378228.
- ↑ Kouichi Yamaguchi, Kenji Sakamoto, Toshio Sakamoto, Yoshiji Fujimoto: A Neural Network for Speaker-Independent Isolated Word Recognition. First International Conference on Spoken Language Processing (ICSLP 1990). Kobe, Japan November 1990 (englisch, isca-speech.org ( des vom 7. März 2021 im Internet Archive) [abgerufen am 13. August 2022]). Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.
- ↑ Benjamin Graham: Fractional Max-Pooling. 18. Dezember 2014, arxiv:1412.6071.
- ↑ Dominik Scherer, Andreas C. Müller, Sven Müller: Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. Artificial Neural Networks (ICANN), 20th International Conference on. Springer, Thessaloniki, Greece 2010, S. 92–101 (englisch, uni-bonn.de [PDF]).
- ↑ Josif Grabocka, Stiftung Universität Hildesheim: Convolutional Neural Networks (CNN)
- ↑ Zoran Nikolić, Universität zu Köln: Convolutional Neural Networks
- ↑ a b Yann LeCun: LeNet-5, convolutional neural networks. Abgerufen am 17. November 2016.
- ↑ P. Mazzoni, R. A. Andersen, M. I. Jordan: A more biologically plausible learning rule than backpropagation applied to a network model of cortical area 7a. In: Cerebral cortex. Band 1, Nummer 4, 1991 Jul-Aug, S. 293–307, doi:10.1093/cercor/1.4.293, PMID 1822737.
- ↑ a b Yoshua Bengio: Towards Biologically Plausible Deep Learning. Februar 2015, arxiv:1502.04156v3 (englisch).
- ↑ Haiguang Wen: Neural Encoding and Decoding with Deep Learning for Dynamic Natural Vision. August 2016, arxiv:1608.03425 (englisch).
- ↑ Sandy Wiraatmadja: Modeling the Visual Word Form Area Using a Deep Convolutional Neural Network. (PDF) Abgerufen am 17. September 2017 (englisch).
- ↑ J. G. Daugman: Uncertainty relation for resolution in space, spatial frequency, and orientation optimized by two-dimensional visual cortical filters. In: Journal of the Optical Society of America A, 2 (7): 1160–1169, July 1985.
- ↑ S. Marčelja: Mathematical description of the responses of simple cortical cells. In: Journal of the Optical Society of America. Band 70, Nr. 11, 1980, S. 1297–1300, doi:10.1364/JOSA.70.001297.
- ↑ ImageNet Classification with Deep Convolutional Neural Networks, A. Krizhevsky, I. Sutskever and G. E. Hinton (PDF; 1,4 MB)
- ↑ The “Independent Components” of Scenes are Edge Filters (PDF; 1,3 MB), A. Bell, T. Sejnowski, 1997, abgerufen am 17. November 2016.
- ↑ baeldung.com: Introduction to Convolutional Neural Networks
- ↑ ImageNet Classification with Deep Convolutional Neural Networks (PDF; 1,4 MB)
- ↑ Dan Ciresan, Ueli Meier, Jürgen Schmidhuber: Multi-column deep neural networks for image classification. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition. Institute of Electrical and Electronics Engineers (IEEE), New York, NY Juni 2012, S. 3642–3649, doi:10.1109/CVPR.2012.6248110, arxiv:1202.2745v1 (Online [abgerufen am 9. Dezember 2013]).
- ↑ ILSVRC 2016 Results
- ↑ Improving multiview face detection with multi-task deep convolutional neural networks
- ↑ A Deep Architecture for Semantic Parsing. Abgerufen am 17. November 2016 (englisch).
- ↑ Learning Semantic Representations Using Convolutional Neural Networks for Web Search – Microsoft Research. In: research.microsoft.com. Abgerufen am 17. November 2016 (englisch).
- ↑ A Convolutional Neural Network for Modelling Sentences. 17. November 2016 (englisch).
- ↑ Convolutional Neural Networks for Sentence Classification. Abgerufen am 17. November 2016 (englisch).
- ↑ Natural Language Processing (almost) from Scratch. Abgerufen am 17. November 2016 (englisch).
- ↑ heise online: Maschinelle Übersetzer: DeepL macht Google Translate Konkurrenz. 29. August 2017, abgerufen am 18. September 2017.
- ↑ Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness: Human-level control through deep reinforcement learning. In: Nature. Band 518, Nr. 7540, Februar 2015, ISSN 0028-0836, S. 529–533, doi:10.1038/nature14236.
- ↑ Rani, G. E., Venkatesh, E., Balaji, K., Yugandher, B., Kumar, A. N., & SakthiMohan, M. (2022, April). An automated prediction of crop and fertilizer disease using Convolutional Neural Networks (CNN). In 2022 2nd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE) (pp. 1990–1993). IEEE.
- ↑ Sethy, P. K., Barpanda, N. K., Rath, A. K., & Behera, S. K. (2020). Nitrogen deficiency prediction of rice crop based on convolutional neural network. Journal of Ambient Intelligence and Humanized Computing, 11(11), 5703-5711.